

When handling sensitive data in today’s regulatory landscape, especially in industries like finance, healthcare, and telecommunications, selecting the right data anonymization tool is crucial. Whether you’re working on development, testing, or analytics, it’s essential to ensure that your data remains secure while still being useful. But with so many options available, how do you choose the right anonymization tool for your specific needs?
This guide is specifically designed for DevOps teams, data engineers, and security professionals who need to anonymize sensitive data for non-production environments without compromising compliance or referential integrity. This guide will walk you through different data anonymization tools, techniques, explain when and why to use each, and help you identify the best option for your organization—whether you’re managing complex databases, ensuring compliance, or both.
What Are Data Anonymization Tools, and Why Do You Need Them?
Data anonymization transforms sensitive information into a form that protects privacy but still allows organizations to utilize the data. This process is essential for industries facing strict data protection regulations like GDPR, HIPAA, or PCI-DSS.
Common types of anonymization tools include:
- Static Data Masking (SDM)
- Dynamic Data Masking (DDM)
- Tokenization
- Psuedonymization
- Redaction
- Perturbation
- Data shuffling
Each tool offers a different approach to balancing security with data usability, and the choice depends on your organization’s specific needs.
1. Static Data Masking tool: Realistic Anonymization for testing
What it does?
A Static data masking tool permanently replaces sensitive information with anonymized values. Once the data is masked, the changes are irreversible, making this approach particularly useful for non-production environments such as development and testing.
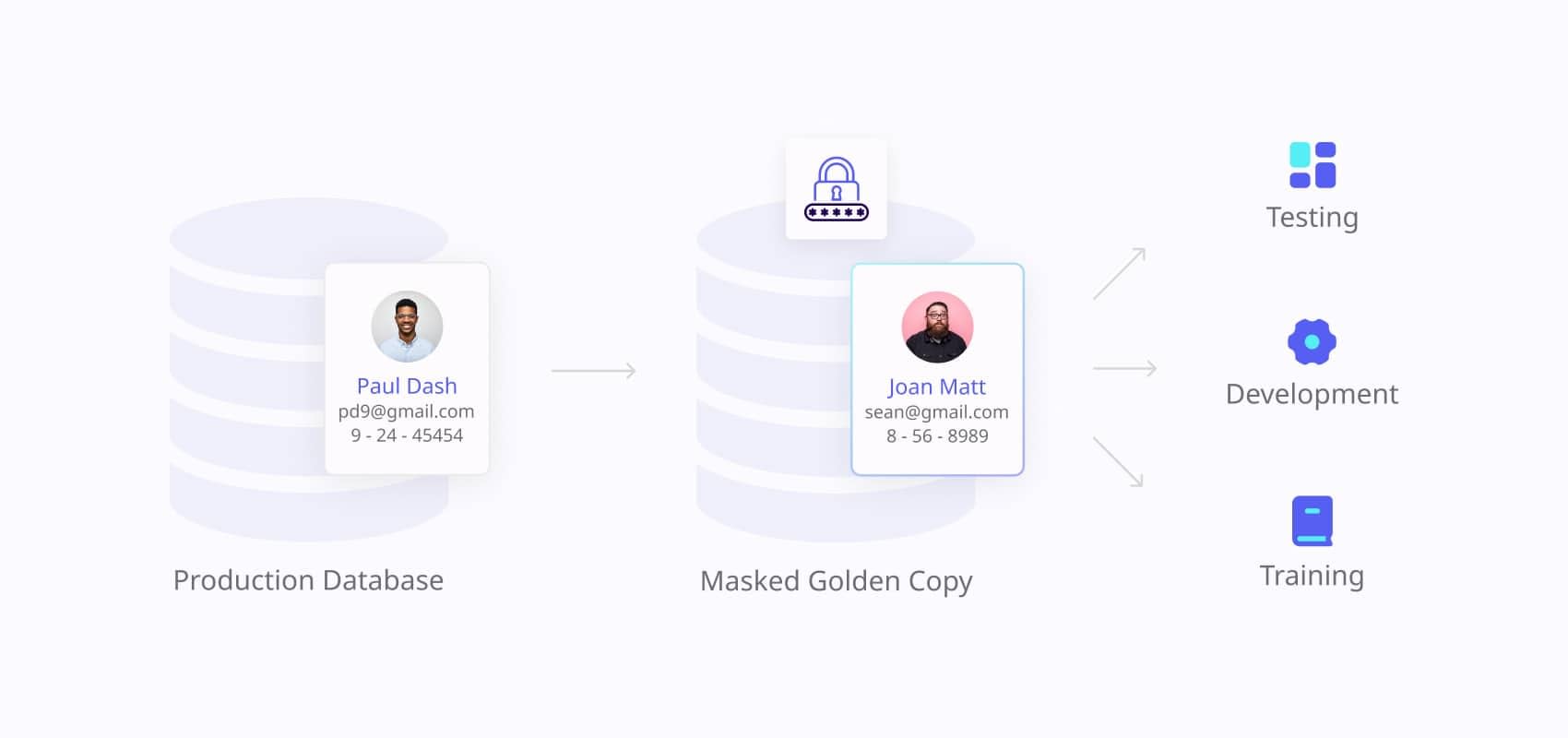
When to use it?
Static data masking is ideal when you need to create test environments that closely replicate production systems. It ensures that sensitive data remains secure while still being fully functional for testing purposes. This technique also allows organizations to reliably source test data for development and securely move it to lower environments without exposing sensitive information. This is particularly crucial for maintaining compliance, especially in highly regulated industries like finance and healthcare.
Example Use Case:
Imagine a bank testing a new fraud detection system. Developers need access to transaction histories, account numbers, and customer information. Static data masking allows them to anonymize sensitive details like names and account numbers while preserving the data’s overall structure and relationships. This ensures accurate testing while protecting the bank’s customer data.
Who benefits the most?
- Financial institutions working with sensitive customer data.
- Healthcare providers needing to anonymize patient records.
- Telecommunications companies managing interconnected systems with customer information.
2. Dynamic Data Masking tool : Real-Time Data Access Control
What it does?
A Dynamic data masking tool alters sensitive data as it’s retrieved, tailoring visibility based on user roles, while leaving the original data unchanged in the database. This feature, first introduced by Microsoft in SQL Server 2016, helps control which users can see sensitive information at the database level without requiring changes to the application.
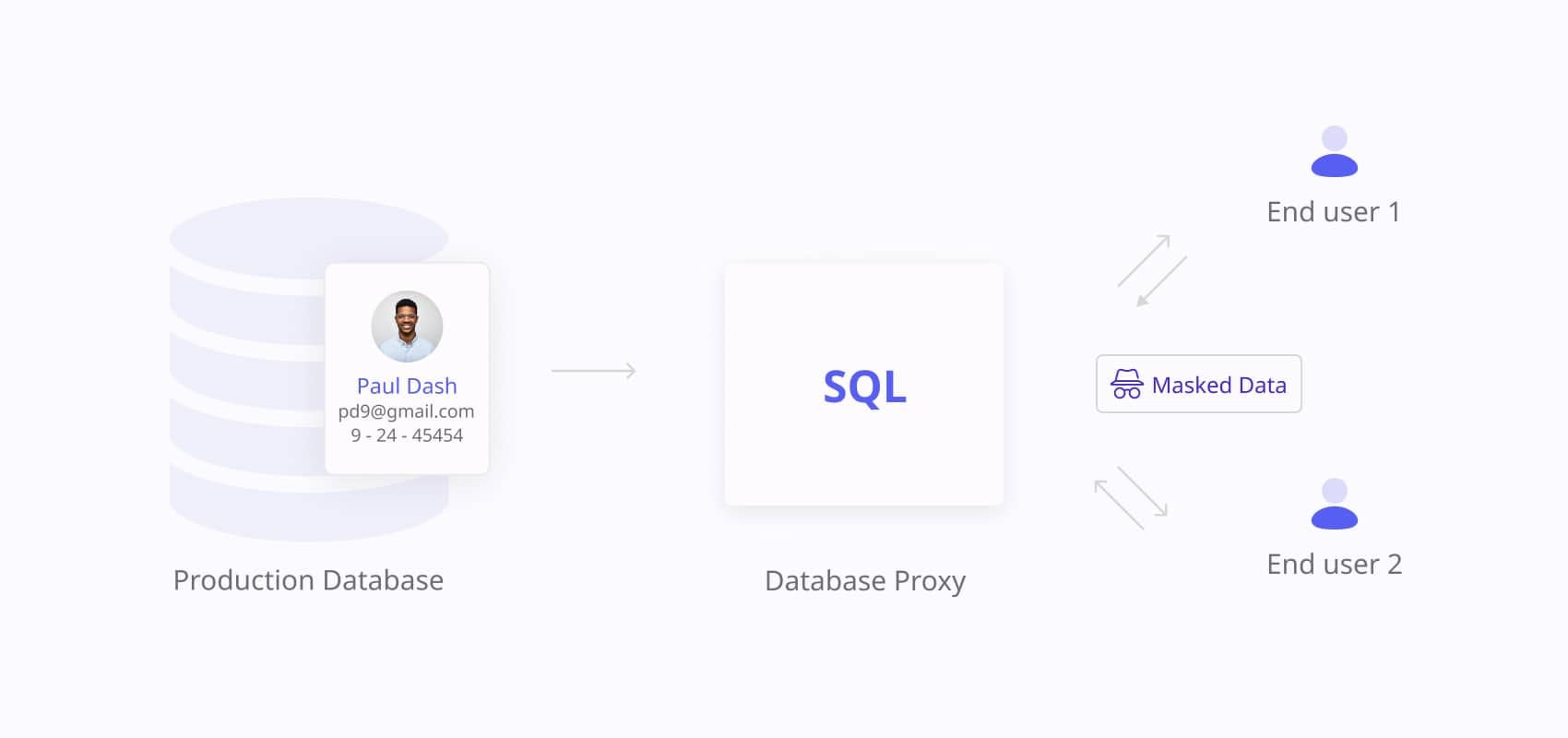
When to use it?
Dynamic masking works best when you need to anonymize data in operational environments without making permanent changes. It’s ideal for restricting access to sensitive information on the fly, such as customer service centers or applications that require different levels of access for different users. For highly sensitive data, such as personal healthcare information, dynamic data masking may present some security challenges as there is a potentially exploitable connection from the masked data to the data source.
Example Use Case:
An e-commerce platform needs to mask customer credit card numbers in its customer support portal. With dynamic masking, most customer service representatives will only see the last four digits of the card, but authorized users, like managers, can see the full number when necessary.
Who benefits most?
- Retailers and e-commerce platforms that need controlled access to sensitive data.
- Customer service support centers or customer service teams managing personal data.
3. Tokenization tool: Replace Sensitive Data with Secure Tokens
What it does?
A Tokenization tool replaces sensitive data with tokens—unique symbols with no inherent meaning—while the original data is stored securely in a separate system. Tokenization is typically used to secure payment information or highly sensitive data like health records.
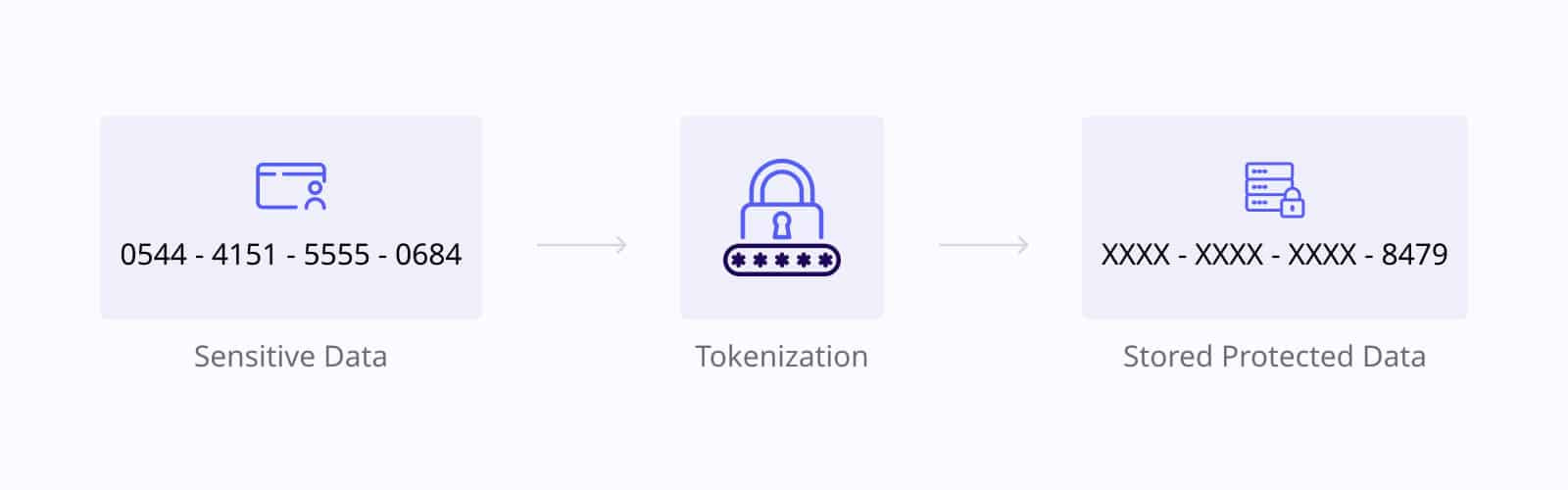
When to use it?
Tokenization is often the preferred method in payment processing systems where you need to protect data such as credit card numbers. Since tokenization doesn’t alter the data format, it can be used seamlessly in environments where the data needs to be processed or referenced.
Example Use Case:
The most common use of tokenization is for protecting payment card information (PCI) in compliance with PCI-DSS standards. In this case, credit card numbers are replaced with tokens, securing the actual data while allowing payment systems to function without exposing sensitive information.
Who benefits the most?
- Payment processors and e-commerce companies dealing with financial data.
- Healthcare organizations managing patient health records
4. Pseudonymization Tool: Replace Data with Reversible Identifiers
What it does?
A pseudonymization tool replaces sensitive data with pseudonyms or identifiers, which can be re-linked to the original data if needed. This technique is useful when some level of traceability is required but direct access to the original data must be restricted.
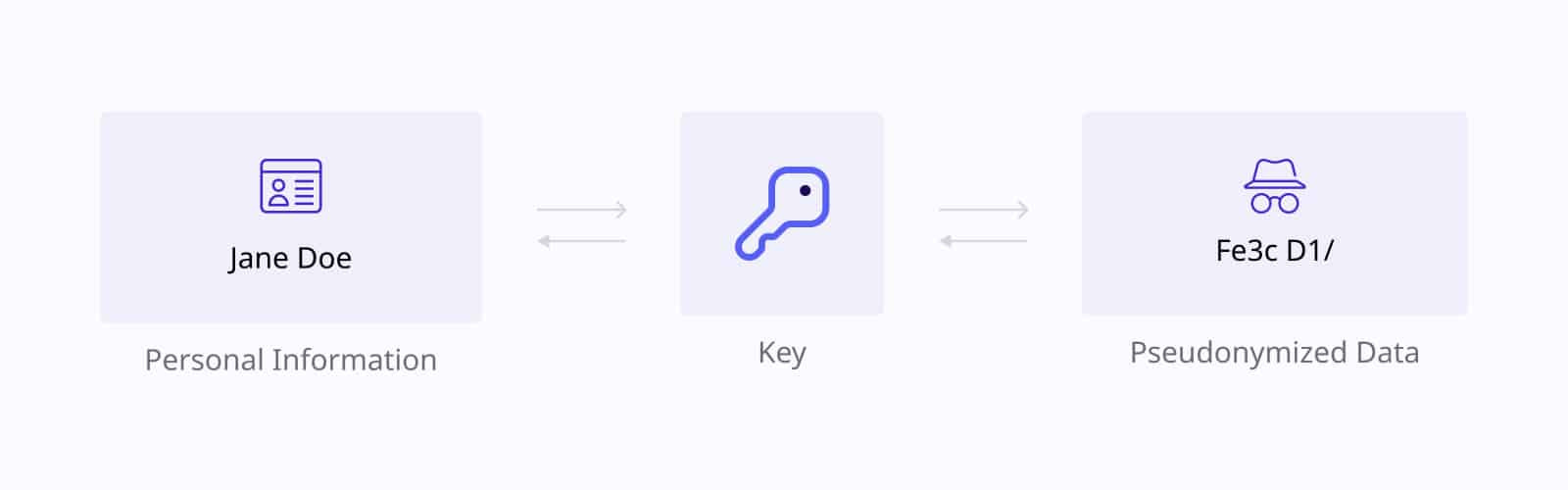
When to use it?
Pseudonymization is often used in healthcare, research, or legal environments where it is necessary to preserve data links without exposing sensitive information. It strikes a balance between data privacy and functionality.
Example Use Case:
A pharmaceutical company conducts clinical trials and uses pseudonymization to replace patient names with IDs. If follow-up research is needed, authorized users can trace back the data to the original participants.
5. Redaction Tool: Remove Sensitive Data Entirely
What it does?
A redaction tool blanks out or removes sensitive data, effectively making it unreadable. This is common in document handling, where sensitive fields such as names, addresses, or account numbers must be hidden but the overall document context is preserved.

When to use it?
Redaction is ideal for reports, documents, or files where sensitive information is irrelevant to the reader but other parts of the content must remain intact. It’s widely used in legal documents, public reports, or any setting where sensitive information must be concealed.
Example Use Case:
A legal team redacts confidential information (such as names or personal identifiers) from a report before submitting it for public review. This ensures privacy while allowing the document to be shared.
6. Perturbation Tool: Add Noise to Data
What it does?
A Perturbation tool introduces noise into data, slightly altering the values to ensure privacy. While this maintains the usefulness of the data for analysis, it obscures individual-level details, making it hard to reverse-engineer the original information.
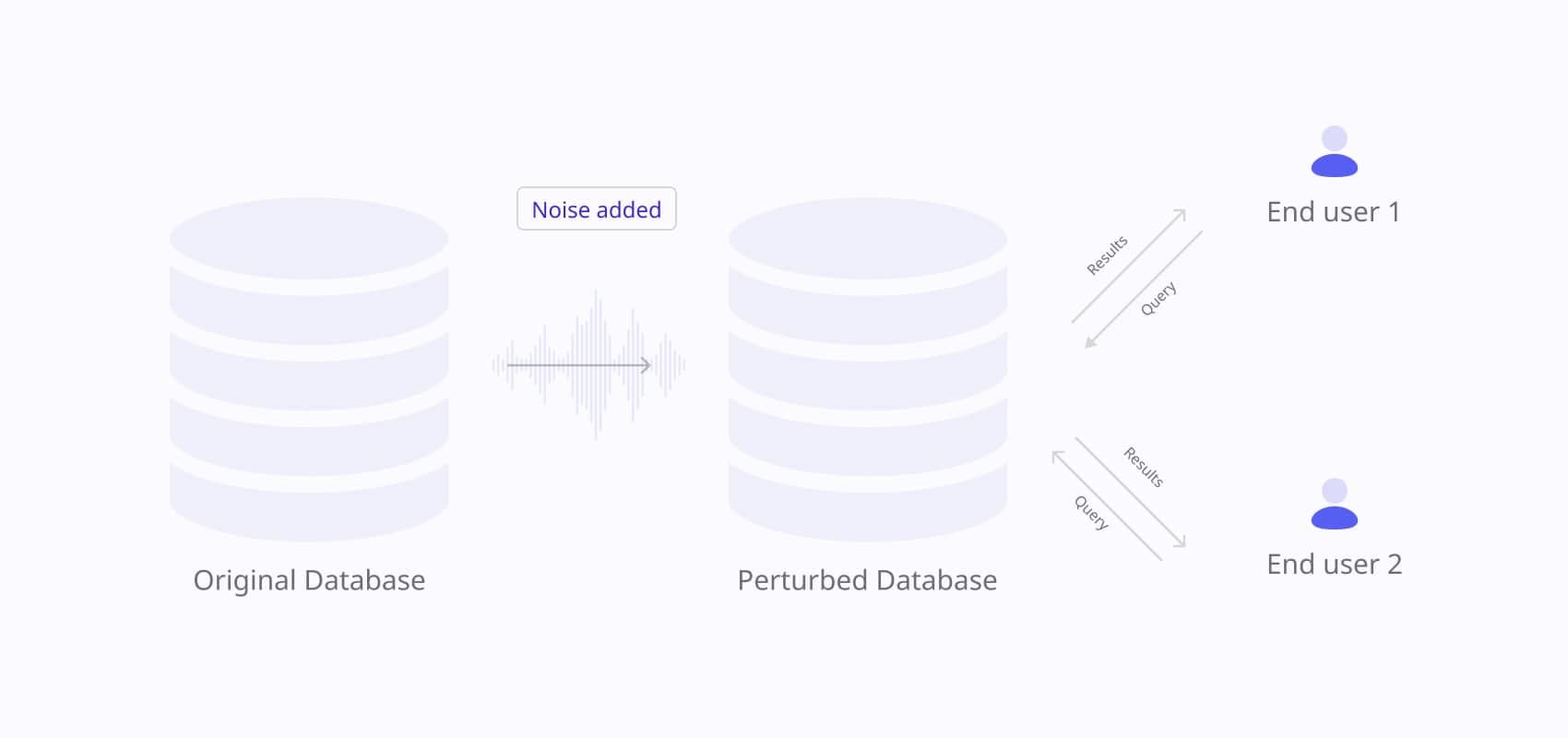
When to use it?
If your organization is focused on large-scale statistical analysis, perturbation allows you to anonymize data without losing the big picture. This is ideal for industries that require anonymized datasets for machine learning or big data analytics. However, for if you need to anonymize data without compromising accuracy, static data masking can achieve the same goal without adding noise.
Example Use Case:
A government agency needs to share anonymized health statistics with researchers. By using perturbation, they can add noise to individual records, ensuring that researchers see the trends without exposing sensitive personal information.
7. Data Shuffling Tool : Randomize Data to Preserve Distribution
What it does?
A Data shuffling tool rearranges values within a dataset to obscure individual details while maintaining the overall distribution of the data. This ensures that the statistical properties of the dataset remain intact, but individual data points lose their original associations.
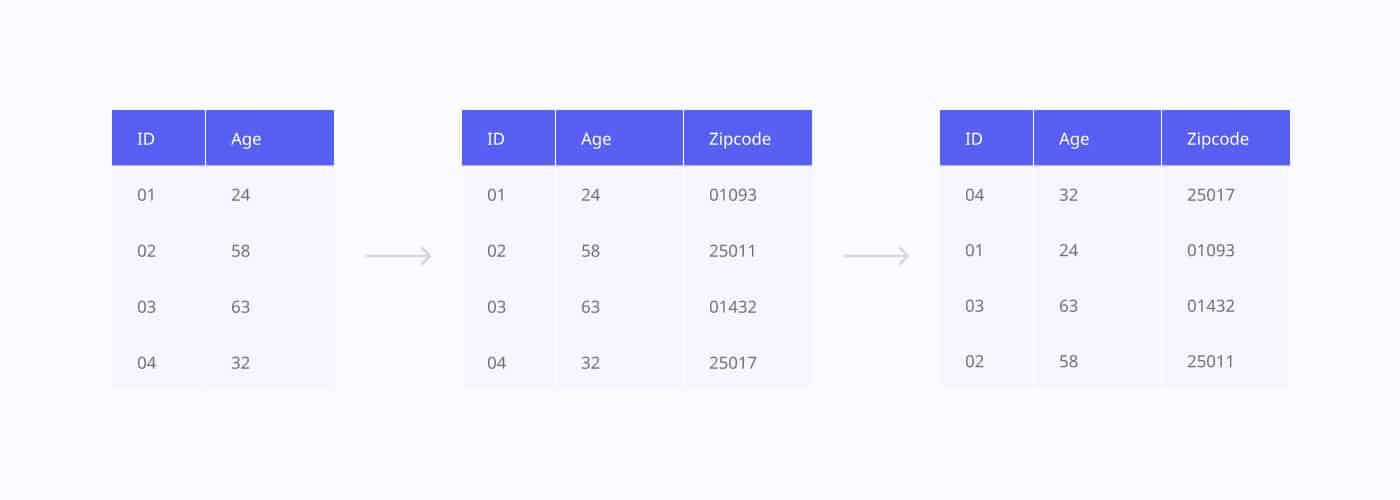
When to use it?
Data shuffling is useful when the goal is to protect sensitive information for research or analytics while preserving the overall trends or patterns in the dataset. It’s commonly used in large-scale data analysis where exact data relationships are less important.
Example Use Case:
A retail company shuffles customer purchase records to anonymize individual transactions for a sales trend analysis. The overall distribution remains accurate, but no individual transaction can be traced back to a specific customer.
Selecting the Right Tool for Your Data
Choosing the right data anonymization tool requires understanding your industry’s needs, your data environment, and the compliance requirements you face. Each anonymization technique has its strengths, and your decision should reflect your organization’s unique requirements.
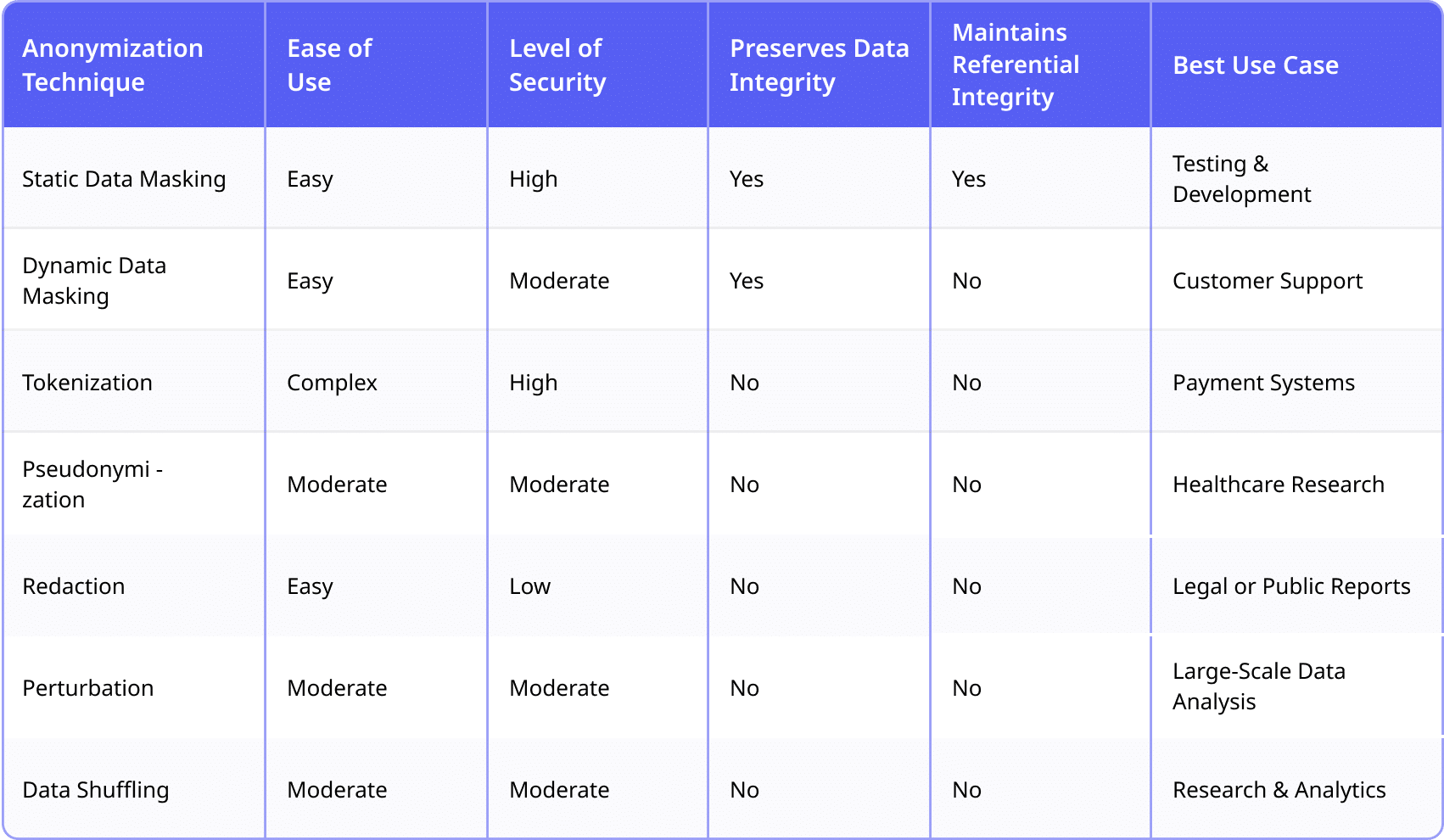
For teams working in regulated industries or those managing complex data environments, static data masking offers strong advantages, particularly when maintaining data accuracy and usability is critical. For environments that demand the highest security, tokenization and encryption provide robust protection but require more complex implementation. Generalization and pseudonymization are great choices for broad analyses and research, though they may sacrifice some data accuracy. Data shuffling is ideal for large-scale analytics where preserving statistical patterns matters more than maintaining individual record consistency. Your choice depends on your industry’s regulations, data sensitivity, and whether usability or security takes precedence.
That said, every organization’s needs are different, and the best solution depends on your use case. The key is to choose the tool that best fits your operational needs while ensuring compliance and data security.
Why Compliance-driven Industries Prefer Static Data Masking
Although all the above techniques serve important roles, static data masking is often the preferred choice in regulated industries with complex data environments. One of the primary reasons is its ability to maintain referential integrity, ensuring that the relationships between datasets remain intact, which is critical for industries like finance, healthcare, and large enterprises that depend on highly interconnected systems. Static data masking allows sensitive information to be anonymized while still retaining full functionality, making it invaluable for development, testing, and analytics environments.
Solutions like ADM discovery + masking tool offer the perfect balance by enabling organizations to secure their data while ensuring usability. By automating the masking process, tools like ADM help enterprises meet stringent GDPR, HIPAA, and PCI-DSS compliance requirements without compromising data structure or integrity. This ensures organizations can work confidently with anonymized data, safeguarding privacy while maintaining productivity and regulatory compliance, making ADM a trusted choice for compliance-driven industries.












Leave a Reply